Chapter4. 빅데이터의 축적
데이터 수집
- 벌크형 데이터 전송: DB나 웹서버에서 SQL, API로 데이터를 추출하여 ETL 서버를 통해 분산 스토리지에 저장한다. 신뢰성이 중요한 경우에는 사용하면 좋다.
- 스트리밍형 데이터 전송: 다수의 클라이언트에서 지속적으로 작은 데이터가 전송된다. 메시지 큐와 메시지 브로커와 같은 중계 시스템을 이용하여 일정한 간격으로 모아서 분산 스토리지에 저장한다.
시계열 데이터 최적화
- 이벤트 시간: 실제 해당 데이터가 생성된 시간. 즉, 실제 분석의 대상이 되는 시간
- 프로세스 시간: 서버가 처리하는 시간
시계열 인덱스: 이벤트 시간에 대해 인덱스를 만들어 데이터 집계를 빠르게 실행할 수 있게 해주는 방법으로 카산드라와 같은 분산 데이터베이스를 이용할 수 있다.
비구조화 데이터의 분산 스토리지
- 키-값 스토어: 모든 데이터를 키값 쌍으로 저장. ex) DynamoDB
- 와이드 칼럼 스토어: 하나의 테이블에 가로와 세로의 2차원 데이터를 쓸 수 있도록 한 데이터베이스. ex) Apache Cassandra
- 도큐먼트 스토어: 스키마리스 데이터를 그대로 저장하고 쿼리를 실행 ex) MongoDB
- 검색 엔진: 텍스트 데이터나 스키마리스 데이터를 집계하는데 자주 사용 ex) Elasticsearch
Ch5. 빅데이터의 파이프라인
워크플로: 정형적인 업무 프로세스와 같이 정해진 업무를 원활하게 진행하기 위한 구조 ex) Airflow, Oozie, Prefect
데이터 플로우: 다단계의 데이터 처리를 그대로 분산 시스템의 내부에서 실행 ex) Spark, Flink
배치 형의 데이터 플로우
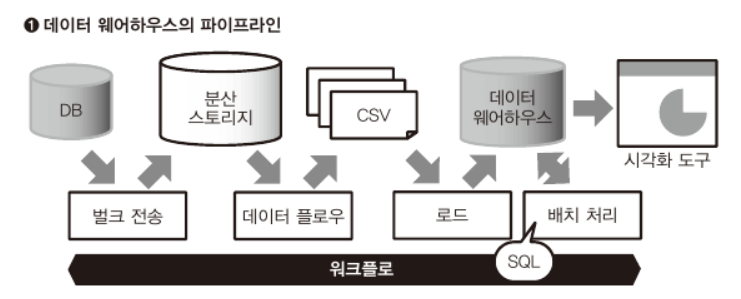
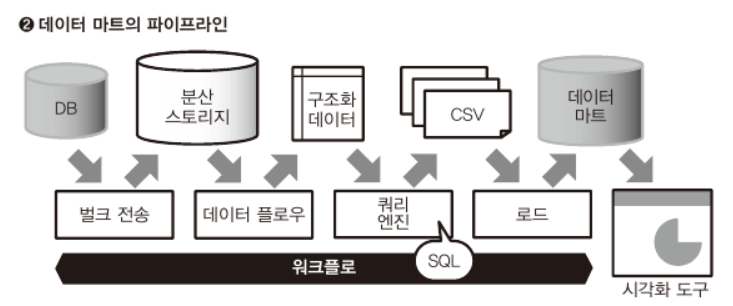
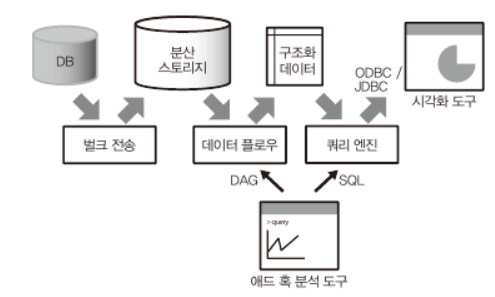
스트리밍 형의 데이터 플로우
스트림 처리: 분산 스토리지를 거치지 않고 처리를 계속하는 것
스트림 처리의 문제 해결
람다 아키텍처, 카파 아키텍처
Ch6. 빅데이터 분석 기반 구축
스키마리스 데이터의 애드 훅 분석
데이터 소스 -> 트위터 스트리밍 API
분산 스토리지 -> 몽고DB
분산 데이터 처리 -> Spark
데이터 정형 -> pandas
대화식 콘솔 -> 주피터 노트북
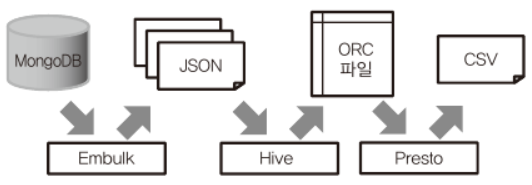
Hadoop에 의한 데이터 파이프라인
데이터 소스 -> 몽고DB
벌크 형 데이터 전송 -> Embulk
분산 시스템 -> Hadoop
데이터 구조화 -> Hive
쿼리 엔진 -> Presto
클라우드 서비스를 이용한 데이터 파이프라인
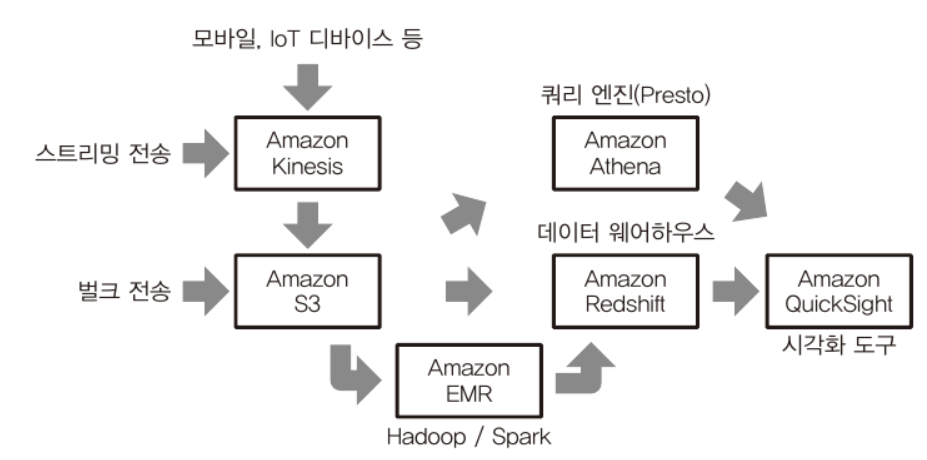
AWS
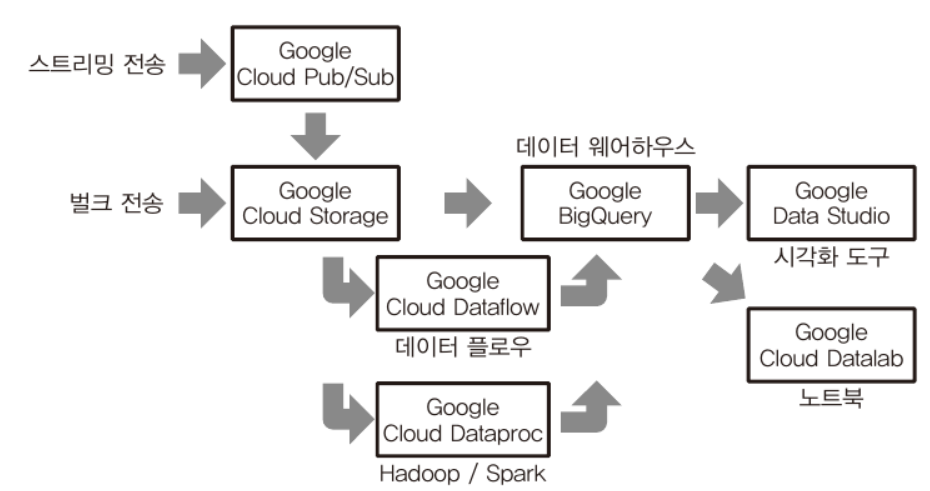
GCP
반응형
'데이터 엔지니어링 > 데이터 엔지니어링 기초' 카테고리의 다른 글
| 데이터 파이프라인 개요 | ETL | 예시 (0) | 2022.08.07 |
|---|---|
| 빅쿼리 데이터 로딩 포맷 비교 CSV | JSON | Parquet | AVRO (0) | 2022.06.08 |
| dbt 꼭 써야할까? dbt 정의/사용이유/필요성 (0) | 2022.05.17 |
| 빅데이터를 지탱하는 기술 키워드 정리 - 上 (0) | 2022.03.18 |
| 데이터 웨어하우스란? (0) | 2022.03.17 |