GCS에서 빅쿼리로 데이터를 이관하는 작업을 하는 도중 현재 사용하고 있는 데이터 포맷에 대한 의문이 생겼다. 현재는 CSV 파일과 JSON 형태를 사용하고 있었는데, 이게 생각보다 용량을 차지하기도 하고, 특히 CSV 파일은 데이터 오염에 취약한 포맷이라는 이야기를 얼핏 들은 적이 있었다.
특히 데이터 용량 같은 경우 가난한 학생으로써 무료 크레딧을 이용하고 있는데, 생각보다 금방 금방 닳아가는 요금을 보면 가슴이 너무 아팠다. 그러던 중 예전에 하둡을 공부하다가 Parquet이라는 데이터 포맷 형태가 기억이 났고, 조금 더 효율적인 방법을 탐색해보기로 하였다.
우선 빅쿼리에 적재할 수 있는 형태가 크게 CSV, JSON, Parquet, AVRO 4가지로 나눠볼 수 있었다. 하나하나씩 특징을 알아보고 내 프로젝트에서는 어떤 형태를 사용해보는 것이 좋을 지 알아보려고 한다. 빅쿼리 공식 문서에서 포맷별 유의사항을 참고하면서 하나 씩 알아보도록 하자.
CSV
데이터 분석을 해본 사람들은 가장 친숙한 형태일 것이다. 쉼표로 구분된 데이터로 엑셀로 확인가능한 굉장히 편리한 데이터 형식이다. 빅쿼리에 로드할 때 유의할 점은 다음과 같다. 주목할 부분은 볼드체로 처리해보았다.
- CSV 파일은 중첩되거나 반복되는 데이터는 지원하지 않습니다.
- 바이트 순서 표시(BOM) 문자를 삭제합니다.
- 압축된 파일과 압축되지 않은 파일을 같은 로드 작업에 모두 포함할 수는 없습니다.
- gzip 파일의 최대 크기는 4GB입니다.
- CSV나 JSON 데이터를 로드할 때 DATE 열의 값은 대시(-) 구분 기호를 사용해야 하며 날짜는 YYYY-MM-DD(년-월-일) 형식이어야 합니다.
- JSON이나 CSV 데이터를 로드할 때 TIMESTAMP 열의 값은 타임스탬프 날짜 부분에 대시(-) 구분 기호를 사용해야 하며 날짜는 YYYY-MM-DD(년-월-일) 형식이어야 합니다. 타임스탬프의 hh:mm:ss(시간-분-초) 부분에는 콜론(:) 구분 기호를 사용해야 합니다.
여기서 중요한 항목은 첫번째와 네번째 정도일 거 같다. 우선 CSV는 중첩된 데이터를 저장할 수 없다. 나 같은 경우에도 JSON이나 리스트 형태로 되어 있는 데이터가 있어서 해당 데이터를 로드할 때 계속 문자열 형태로 저장되어 애를 좀 먹었었다. 만약 중첩되거나(JSON) 반복되는(리스트) 데이터가 있다면 CSV 형태는 피하는 것을 추천한다.
또한 CSV는 압축한다면 4GB까지 업로드가 가능하다는 것도 알아두면 좋을 거 같다.
JSON
JSON은 REST API를 사용할 때 가장 많이 사용하는 방식으로 요즘 가장 많이 통용되는 방식이다.
- JSON 데이터는 줄바꿈으로 구분되어야 합니다. 파일에서 각 JSON 객체가 별도의 줄에 있어야 합니다.
- gzip 압축을 사용하면 BigQuery는 데이터를 동시에 읽지 못합니다. 압축한 JSON 데이터를 BigQuery로 로드하는 작업은 비압축 데이터 로드보다 시간이 더 걸립니다.
- 압축된 파일과 압축되지 않은 파일을 같은 로드 작업에 모두 포함할 수는 없습니다.
- gzip 파일의 최대 크기는 4GB입니다.
- BigQuery는 순수 JSON 사전에 스키마 정보가 부족할 수 있기 때문에 JSON 형식의 지도나 사전을 지원하지 않습니다. 예를 들어 "products": {"my_product": 40.0, "product2" : 16.5} 장바구니에 있는 제품 목록을 표시하는 것은 유효하지 않지만 "products": [{"product_name": "my_product", "amount": 40.0}, {"product_name": "product2", "amount": 16.5}]는 유효합니다.
- 전체 JSON 객체를 유지해야 하는 경우 JSON 함수를 사용하여 쿼리할 수 있는 string 열에 입력해야 합니다.
- BigQuery API를 사용해서 [-253+1, 253-1] 범위 밖의 정수(일반적으로 9,007,199,254,740,991을 초과하는 정수)를 정수(INT64) 열에 로드하려는 경우 데이터 손상 방지를 위해 이를 문자열로 전달합니다. 이 문제는 JSON/ECMAScript의 정수 크기 제한으로 인해 발생합니다. 자세한 내용은 RFC 7159의 숫자 섹션을 참조하세요.
- CSV나 JSON 데이터를 로드할 때 DATE 열의 값은 대시(-) 구분 기호를 사용해야 하며 날짜는 YYYY-MM-DD(년-월-일) 형식이어야 합니다.
- JSON이나 CSV 데이터를 로드할 때 TIMESTAMP 열의 값은 타임스탬프 날짜 부분에 대시(-) 구분 기호를 사용해야 하며 날짜는 YYYY-MM-DD(년-월-일) 형식이어야 합니다. 타임스탬프의 hh:mm:ss(시간-분-초) 부분에는 콜론(:) 구분 기호를 사용해야 합니다.
우선 JSON을 빅쿼리에 로드할 때 가장 중요한 점은 그냥 JSON으로는 로드가 되지 않고 꼭 NDJSON 형태로 로드하여야 한다는 것이다. NDJSON은 Newline Delimited JSON로 줄바꿈으로 구분된 JSON을 말한다. ndjson 라이브러리를 사용할 수도 있고, 판다스에서는 df.to_json({file_path}, orient='records', lines=True)으로 변환할 수도 있다.
JSON도 CSV와 같이 로드 가능한 압축 파일 용량은 4GB이다. 또한 JSON을 로드할 때는 정확한 스키마 인식을 위해 5번째처럼 칼럼을 확실하게 구분지을 수 있도록 해주어야 한다.
하둡과 데이터 포맷 (Avro, Parquet, ORC)
여기서부터는 아마 조금은 생소한 데이터 포맷일 것이다. Avro, Parquet, ORC 모두 하둡에 최적화된 데이터 저장 포맷이다. JSON이나 CSV로 하둡에 저장할 수는 있지만 그렇게 효율적인 방법은 아니다.
이러한 파일 형식은 기본적으로 유사한 특징을 가지고 있지만, 각각 고유하며 상대적인 장점과 단점이 있다. 그 부분들은 한 번 간단하게 알아보도록 하자.
공통점
세 가지 모두 하둡에 최적화되어 있고, 압축을 할 수 있게끔 해준다. 또한 바이너리 형식이기 때문에 사람이 읽을 수 있는 형식이 아닌 기계가 읽을 수 있는 형식으로 되어 있다. 따라서 사람이 읽어야 한다면 이 포맷을 조금 재고해볼 필요가 있다.
그리고 이 데이터 포맷들의 가장 장점 중 하나가 여러 디스크에 분할하여 저장할 수 있는 확장성과 병렬성이다. 세 형식 모두 나누어진 파일 자체에 스키마를 전달하기 때문에 하나의 파일만 가지고 와도 다른 시스템에 로드하면 데이터가 무엇인지 정확하게 알 수 있다.
차이점
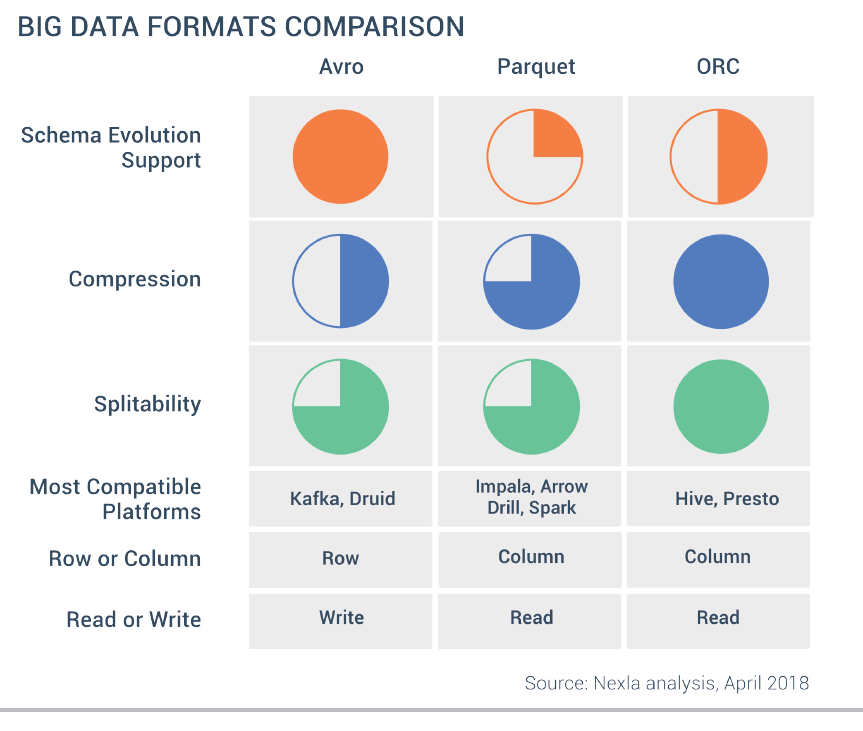
가장 큰 차이점은 데이터를 저장하는 방식이다. Parquet과 ORC은 열 기반이고, Avro는 행 기반으로 데이터를 저장한다. 열 기반은 읽기에, 행 기반은 쓰기에 최적화되어 있는 방식이다. 차이를 위해 예시를 들어보도록 하자.
만약 직원이 100만 명인 대기업에서 경영진은 직원에게 지급되는 급여를 각 위치별로 그룹화하여 찾고자 한다. 만약 급여 및 위치 데이터 세트가 열 지향 방식으로 저장되는 경우 이 두 열의 데이터만 만지면 된다. 하지만 행 단위로 수행하려면 수백만 개의 행을 가져와서 각 행에 대해 작업을 수행해야 한다.
따라서 전체 데이터 세트에서 매우 적은 수의 열에 대해 프로젝션을 수행하려는 상황에서는 열 기반 형식이 행 기반 형식보다 훨씬 더 좋다고 한다.
위에서 볼 수 있다시피 읽기 성능은 열 기반 형식이 더 좋다고 할 수 있고, 반대로 쓰기 성능은 행 기반 형식인 Avro가 더 좋다고 할 수 있다. 또한 추론할 수 있듯이 열 기반 방식이 압축률이 더 좋다. 아래의 그림은 세 가지 포맷에 대한 비교를 간단하게 표로 나타내었다.
빅쿼리에 효율적으로 데이터 로드하는 방법
일단 데이터 용량을 고려하여 데이터를 압축하여 로드할 수 있다. 하지만 압축된 파일은 병렬로 로드할 수 없기 때문에, 압축되지 않은 CSV 파일이나 다른 파일 형식을 고려한다. 그렇다면 빅쿼리에 데이터를 효율적으로 로드하려면 어떻게 해야할까?
우선 위에서 살펴보았던 Avro를 생각해볼 수 있다. Avro는 블록으로 분할하고 블록별로 압축할 수 있는 자체 설명 바이너리 파일을 사용하는데, 이는 데이터를 병렬로 로드할 수 있게해준다. 아무래도 블록별로 압축되어 있기 때문에 데이터 용량도 작고, 무엇보다 중첩 구조를 사용할 수 있다. 그리고 스키마의 변화가 있을 때 유연하게 대처할 수도 있다.
하지만 바이너리 데이터이기 때문에 가독성이 매우 안좋고, 다양한 소스(GCS, RDS...)와 결합하여 사용하는 연합 쿼리 측면에서 비효율적인 단점이 있다.
반면 Avro와 비슷하지만 다른 Parquet이라는 형태도 생각해볼 수 있다. Avro와 매우 비슷하지만 가장 큰 차이는 위에서 설명했다시피 열 단위로 저장된다는 것이다. 이는 데이터를 로드할 때 모든 열을 읽어야 하므로 다소 비효율적이지만, 연합 쿼리를 사용하려는 경우는 Avro보다 효율적이다.
+추가적으로 행 기반은 Full Scan이나 모든 칼럼을 다 사용하는 쿼리일 경우 적합하고, 열 기반은 일부 컬럼만 스캔할 때 효율적이라고 한다.
나의 경우는?
내 빅쿼리에는 총 4개의 테이블(user, score, course, problem)이 저장되어 있는 상태이다. 이 중 가장 용량도 크고 스캔도 많이 하는 테이블인 score을 기준으로 잡고 생각해보자. 우선 3일에 한 번 데이터가 업로드되고, 용량은 200~300MB 정도로 예상된다. 또한 모든 칼럼을 다 사용하는 것이 아니라 일부 칼럼만 스캔된다. 그리고 데이터 크기가 얼마 되지는 않아 로딩속도는 포맷별로 크게 차이가 나지 않아서 핵심 고려사항은 아니다.
위와 같이 나의 케이스를 분석해본 결과 이번 프로젝트에서는 Parquet이 가장 적절하였다. Avro가 빅쿼리에서 권장하는 포맷이긴 하지만 프로젝트 방향과 맞고, 무엇보다 예전부터 한 번 써보고 싶었던 포맷이었다 ㅎㅎ
적용과정은 따로 산타 백준 프로젝트 글을 포스팅할 예정이니 만약 궁금하다면 해당 글을 참고하면 좋을 거 같다!
참고
Big Data File Formats Demystified
Big Data File Formats Demystified
So you're filling your Hadoop cluster with reams of raw data, and your data analysts and scientists are champing at the bit to get started. Then the
www.datanami.com
빅쿼리 데이터 로딩하기
구글 클라우드 시작하기 구글 빅쿼리 데이터 로딩하기 나무기술 최유석 개요 구글의 대용량 데이터 분석 서비스인 빅쿼리에 구글 클라우드 스토리지를 활용하여 CSV, JSON형식의 데이터를 로드하
whitechoi.tistory.com
How to load data efficiently in BigQuery
How to load data efficiently in BigQuery
There are always different methods and files to load data from local store or Google Cloud Storage. The first thing to look at is, are…
medium.com
'데이터 엔지니어링 > 데이터 엔지니어링 기초' 카테고리의 다른 글
| 데이터 파이프라인 개요 | ETL | 예시 (0) | 2022.08.07 |
|---|---|
| 빅데이터를 지탱하는 기술 키워드 정리 - 下 (0) | 2022.06.24 |
| dbt 꼭 써야할까? dbt 정의/사용이유/필요성 (0) | 2022.05.17 |
| 빅데이터를 지탱하는 기술 키워드 정리 - 上 (0) | 2022.03.18 |
| 데이터 웨어하우스란? (0) | 2022.03.17 |
GCS에서 빅쿼리로 데이터를 이관하는 작업을 하는 도중 현재 사용하고 있는 데이터 포맷에 대한 의문이 생겼다. 현재는 CSV 파일과 JSON 형태를 사용하고 있었는데, 이게 생각보다 용량을 차지하기도 하고, 특히 CSV 파일은 데이터 오염에 취약한 포맷이라는 이야기를 얼핏 들은 적이 있었다.
특히 데이터 용량 같은 경우 가난한 학생으로써 무료 크레딧을 이용하고 있는데, 생각보다 금방 금방 닳아가는 요금을 보면 가슴이 너무 아팠다. 그러던 중 예전에 하둡을 공부하다가 Parquet이라는 데이터 포맷 형태가 기억이 났고, 조금 더 효율적인 방법을 탐색해보기로 하였다.
우선 빅쿼리에 적재할 수 있는 형태가 크게 CSV, JSON, Parquet, AVRO 4가지로 나눠볼 수 있었다. 하나하나씩 특징을 알아보고 내 프로젝트에서는 어떤 형태를 사용해보는 것이 좋을 지 알아보려고 한다. 빅쿼리 공식 문서에서 포맷별 유의사항을 참고하면서 하나 씩 알아보도록 하자.
CSV
데이터 분석을 해본 사람들은 가장 친숙한 형태일 것이다. 쉼표로 구분된 데이터로 엑셀로 확인가능한 굉장히 편리한 데이터 형식이다. 빅쿼리에 로드할 때 유의할 점은 다음과 같다. 주목할 부분은 볼드체로 처리해보았다.
- CSV 파일은 중첩되거나 반복되는 데이터는 지원하지 않습니다.
- 바이트 순서 표시(BOM) 문자를 삭제합니다.
- 압축된 파일과 압축되지 않은 파일을 같은 로드 작업에 모두 포함할 수는 없습니다.
- gzip 파일의 최대 크기는 4GB입니다.
- CSV나 JSON 데이터를 로드할 때 DATE 열의 값은 대시(-) 구분 기호를 사용해야 하며 날짜는 YYYY-MM-DD(년-월-일) 형식이어야 합니다.
- JSON이나 CSV 데이터를 로드할 때 TIMESTAMP 열의 값은 타임스탬프 날짜 부분에 대시(-) 구분 기호를 사용해야 하며 날짜는 YYYY-MM-DD(년-월-일) 형식이어야 합니다. 타임스탬프의 hh:mm:ss(시간-분-초) 부분에는 콜론(:) 구분 기호를 사용해야 합니다.
여기서 중요한 항목은 첫번째와 네번째 정도일 거 같다. 우선 CSV는 중첩된 데이터를 저장할 수 없다. 나 같은 경우에도 JSON이나 리스트 형태로 되어 있는 데이터가 있어서 해당 데이터를 로드할 때 계속 문자열 형태로 저장되어 애를 좀 먹었었다. 만약 중첩되거나(JSON) 반복되는(리스트) 데이터가 있다면 CSV 형태는 피하는 것을 추천한다.
또한 CSV는 압축한다면 4GB까지 업로드가 가능하다는 것도 알아두면 좋을 거 같다.
JSON
JSON은 REST API를 사용할 때 가장 많이 사용하는 방식으로 요즘 가장 많이 통용되는 방식이다.
- JSON 데이터는 줄바꿈으로 구분되어야 합니다. 파일에서 각 JSON 객체가 별도의 줄에 있어야 합니다.
- gzip 압축을 사용하면 BigQuery는 데이터를 동시에 읽지 못합니다. 압축한 JSON 데이터를 BigQuery로 로드하는 작업은 비압축 데이터 로드보다 시간이 더 걸립니다.
- 압축된 파일과 압축되지 않은 파일을 같은 로드 작업에 모두 포함할 수는 없습니다.
- gzip 파일의 최대 크기는 4GB입니다.
- BigQuery는 순수 JSON 사전에 스키마 정보가 부족할 수 있기 때문에 JSON 형식의 지도나 사전을 지원하지 않습니다. 예를 들어 "products": {"my_product": 40.0, "product2" : 16.5} 장바구니에 있는 제품 목록을 표시하는 것은 유효하지 않지만 "products": [{"product_name": "my_product", "amount": 40.0}, {"product_name": "product2", "amount": 16.5}]는 유효합니다.
- 전체 JSON 객체를 유지해야 하는 경우 JSON 함수를 사용하여 쿼리할 수 있는 string 열에 입력해야 합니다.
- BigQuery API를 사용해서 [-253+1, 253-1] 범위 밖의 정수(일반적으로 9,007,199,254,740,991을 초과하는 정수)를 정수(INT64) 열에 로드하려는 경우 데이터 손상 방지를 위해 이를 문자열로 전달합니다. 이 문제는 JSON/ECMAScript의 정수 크기 제한으로 인해 발생합니다. 자세한 내용은 RFC 7159의 숫자 섹션을 참조하세요.
- CSV나 JSON 데이터를 로드할 때 DATE 열의 값은 대시(-) 구분 기호를 사용해야 하며 날짜는 YYYY-MM-DD(년-월-일) 형식이어야 합니다.
- JSON이나 CSV 데이터를 로드할 때 TIMESTAMP 열의 값은 타임스탬프 날짜 부분에 대시(-) 구분 기호를 사용해야 하며 날짜는 YYYY-MM-DD(년-월-일) 형식이어야 합니다. 타임스탬프의 hh:mm:ss(시간-분-초) 부분에는 콜론(:) 구분 기호를 사용해야 합니다.
우선 JSON을 빅쿼리에 로드할 때 가장 중요한 점은 그냥 JSON으로는 로드가 되지 않고 꼭 NDJSON 형태로 로드하여야 한다는 것이다. NDJSON은 Newline Delimited JSON로 줄바꿈으로 구분된 JSON을 말한다. ndjson 라이브러리를 사용할 수도 있고, 판다스에서는 df.to_json({file_path}, orient='records', lines=True)으로 변환할 수도 있다.
JSON도 CSV와 같이 로드 가능한 압축 파일 용량은 4GB이다. 또한 JSON을 로드할 때는 정확한 스키마 인식을 위해 5번째처럼 칼럼을 확실하게 구분지을 수 있도록 해주어야 한다.
하둡과 데이터 포맷 (Avro, Parquet, ORC)
여기서부터는 아마 조금은 생소한 데이터 포맷일 것이다. Avro, Parquet, ORC 모두 하둡에 최적화된 데이터 저장 포맷이다. JSON이나 CSV로 하둡에 저장할 수는 있지만 그렇게 효율적인 방법은 아니다.
이러한 파일 형식은 기본적으로 유사한 특징을 가지고 있지만, 각각 고유하며 상대적인 장점과 단점이 있다. 그 부분들은 한 번 간단하게 알아보도록 하자.
공통점
세 가지 모두 하둡에 최적화되어 있고, 압축을 할 수 있게끔 해준다. 또한 바이너리 형식이기 때문에 사람이 읽을 수 있는 형식이 아닌 기계가 읽을 수 있는 형식으로 되어 있다. 따라서 사람이 읽어야 한다면 이 포맷을 조금 재고해볼 필요가 있다.
그리고 이 데이터 포맷들의 가장 장점 중 하나가 여러 디스크에 분할하여 저장할 수 있는 확장성과 병렬성이다. 세 형식 모두 나누어진 파일 자체에 스키마를 전달하기 때문에 하나의 파일만 가지고 와도 다른 시스템에 로드하면 데이터가 무엇인지 정확하게 알 수 있다.
차이점
가장 큰 차이점은 데이터를 저장하는 방식이다. Parquet과 ORC은 열 기반이고, Avro는 행 기반으로 데이터를 저장한다. 열 기반은 읽기에, 행 기반은 쓰기에 최적화되어 있는 방식이다. 차이를 위해 예시를 들어보도록 하자.
만약 직원이 100만 명인 대기업에서 경영진은 직원에게 지급되는 급여를 각 위치별로 그룹화하여 찾고자 한다. 만약 급여 및 위치 데이터 세트가 열 지향 방식으로 저장되는 경우 이 두 열의 데이터만 만지면 된다. 하지만 행 단위로 수행하려면 수백만 개의 행을 가져와서 각 행에 대해 작업을 수행해야 한다.
따라서 전체 데이터 세트에서 매우 적은 수의 열에 대해 프로젝션을 수행하려는 상황에서는 열 기반 형식이 행 기반 형식보다 훨씬 더 좋다고 한다.
위에서 볼 수 있다시피 읽기 성능은 열 기반 형식이 더 좋다고 할 수 있고, 반대로 쓰기 성능은 행 기반 형식인 Avro가 더 좋다고 할 수 있다. 또한 추론할 수 있듯이 열 기반 방식이 압축률이 더 좋다. 아래의 그림은 세 가지 포맷에 대한 비교를 간단하게 표로 나타내었다.
빅쿼리에 효율적으로 데이터 로드하는 방법
일단 데이터 용량을 고려하여 데이터를 압축하여 로드할 수 있다. 하지만 압축된 파일은 병렬로 로드할 수 없기 때문에, 압축되지 않은 CSV 파일이나 다른 파일 형식을 고려한다. 그렇다면 빅쿼리에 데이터를 효율적으로 로드하려면 어떻게 해야할까?
우선 위에서 살펴보았던 Avro를 생각해볼 수 있다. Avro는 블록으로 분할하고 블록별로 압축할 수 있는 자체 설명 바이너리 파일을 사용하는데, 이는 데이터를 병렬로 로드할 수 있게해준다. 아무래도 블록별로 압축되어 있기 때문에 데이터 용량도 작고, 무엇보다 중첩 구조를 사용할 수 있다. 그리고 스키마의 변화가 있을 때 유연하게 대처할 수도 있다.
하지만 바이너리 데이터이기 때문에 가독성이 매우 안좋고, 다양한 소스(GCS, RDS...)와 결합하여 사용하는 연합 쿼리 측면에서 비효율적인 단점이 있다.
반면 Avro와 비슷하지만 다른 Parquet이라는 형태도 생각해볼 수 있다. Avro와 매우 비슷하지만 가장 큰 차이는 위에서 설명했다시피 열 단위로 저장된다는 것이다. 이는 데이터를 로드할 때 모든 열을 읽어야 하므로 다소 비효율적이지만, 연합 쿼리를 사용하려는 경우는 Avro보다 효율적이다.
+추가적으로 행 기반은 Full Scan이나 모든 칼럼을 다 사용하는 쿼리일 경우 적합하고, 열 기반은 일부 컬럼만 스캔할 때 효율적이라고 한다.
나의 경우는?
내 빅쿼리에는 총 4개의 테이블(user, score, course, problem)이 저장되어 있는 상태이다. 이 중 가장 용량도 크고 스캔도 많이 하는 테이블인 score을 기준으로 잡고 생각해보자. 우선 3일에 한 번 데이터가 업로드되고, 용량은 200~300MB 정도로 예상된다. 또한 모든 칼럼을 다 사용하는 것이 아니라 일부 칼럼만 스캔된다. 그리고 데이터 크기가 얼마 되지는 않아 로딩속도는 포맷별로 크게 차이가 나지 않아서 핵심 고려사항은 아니다.
위와 같이 나의 케이스를 분석해본 결과 이번 프로젝트에서는 Parquet이 가장 적절하였다. Avro가 빅쿼리에서 권장하는 포맷이긴 하지만 프로젝트 방향과 맞고, 무엇보다 예전부터 한 번 써보고 싶었던 포맷이었다 ㅎㅎ
적용과정은 따로 산타 백준 프로젝트 글을 포스팅할 예정이니 만약 궁금하다면 해당 글을 참고하면 좋을 거 같다!
참고
Big Data File Formats Demystified
Big Data File Formats Demystified
So you're filling your Hadoop cluster with reams of raw data, and your data analysts and scientists are champing at the bit to get started. Then the
www.datanami.com
빅쿼리 데이터 로딩하기
구글 클라우드 시작하기 구글 빅쿼리 데이터 로딩하기 나무기술 최유석 개요 구글의 대용량 데이터 분석 서비스인 빅쿼리에 구글 클라우드 스토리지를 활용하여 CSV, JSON형식의 데이터를 로드하
whitechoi.tistory.com
How to load data efficiently in BigQuery
How to load data efficiently in BigQuery
There are always different methods and files to load data from local store or Google Cloud Storage. The first thing to look at is, are…
medium.com
'데이터 엔지니어링 > 데이터 엔지니어링 기초' 카테고리의 다른 글
| 데이터 파이프라인 개요 | ETL | 예시 (0) | 2022.08.07 |
|---|---|
| 빅데이터를 지탱하는 기술 키워드 정리 - 下 (0) | 2022.06.24 |
| dbt 꼭 써야할까? dbt 정의/사용이유/필요성 (0) | 2022.05.17 |
| 빅데이터를 지탱하는 기술 키워드 정리 - 上 (0) | 2022.03.18 |
| 데이터 웨어하우스란? (0) | 2022.03.17 |