CPU 스케줄링 개념
CPU 스케줄링은 멀티 프로그래밍된 운영체제에서는 필수이다. 보통 프로그램을 동작시키면 I/O bound가 CPU bound보다 훨씬 많은 일이 빈번하다. 이러한 상황에서 CPU 효율을 높이기 위해 CPU bound를 조금이라도 더 높이려는데에 스케줄링은 매우 중요한 과정이라고 할 수 있다.
CPU 스케줄링이란 대기 상태에 있는 프로세스 중에 어떤 프로세스에 CPU를 할당해줄 것인가를 정하는 과정이다. 다음 프로세스를 선택하는데는 다양한 방법이 있는데, 크게는 FIFO와 우선순위 큐를 이용하는 방법이 있다. 이는 뒤에서 여러 스케줄링 알고리즘을 배우며 알아보도록 하자.
스케줄링에서는 선점형과 비선점형이라는 또 다른 중요한 개념이 있다. 비선점형은 다른 프로세스가 다 끝날 때까지 빼았지 않고 기다리는 것이고, 선점형은 스케줄러에 의해 다양한 알고리즘으로 프로세스를 쫓아내고 다른 프로세스에 CPU를 할당해줄 수 있는 방법이다.
디스패처
디스패처(dispatcher)는 스케줄러가 어떤 프로세스를 기준에 맞게 선택한다면 선택된 프로세스를 CPU에 할당해주는 실제적인 처리 역할을 맡고 있다. 즉, 문맥 교환이 일어날 때 이전의 프로세스의 상태를 저장하고 다음 프로세스를 복원하는 실제 처리 과정을 담당하고 있다. 참고로 디스패처에도 이를 실행하는 시간이 있는데, 이를 dispatcher latency라고 한다. 만약 CPU를 할당하여 사용하는 시간이 디스패처가 dispatcher latency보다 작다면 CPU는 일을 못하고 계속 디스패치만 될 것이다. 따라서 둘의 시간을 알맞게 설정하는 것이 중요하다.
스케줄링 기준
스케줄링을 효율적으로 하기 위해서는 효율성을 측정하기 위한 기준이 있어야 한다. 이러한 기준은 한 가지만 있는 것이 아니라 다양하게 측정할 수 있다. CPU 이용효율이나, 처리량(Throughput: 시간당 완료되는 프로세스 수) 등도 있지만 Wating time(대기 시간)을 기준으로 하는 것이 가장 일반적이다. 대기 시간은 프로세스가 실행되기까지 큐에서 대기한 시간을 말하는데 이것을 최소화해준다면 전체적으로 효율이 올라간다고 할 수 있다.
스케줄링 알고리즘
FCFS
FCFS 알고리즘은 가장 간단한 스케줄링 기법으로 First-Come, First-Served 즉, 먼저 온 프로세스에게 CPU를 할당해주는 FIFO를 사용한 방법이다. 간트 차트를 통해 동작 방식을 살펴보자.

만약 P2, P3, P1 순으로 프로세스가 도착했다면 위와 같이 처리될 것이다. FCFS의 총 대기 시간을 살펴보면, P1은 6, P2는 0, P3는 3이므로 9이고 따라서 평균 대기시간은 9/3=3이라고 할 수 있다. FCFS 알고리즘은 도착한 순서에 따라 처리하는 비선점형 알고리즘이기 때문에 CPU burst time에 따라 효율차이가 크다. 이 말인즉슨 초기의 프로세스의 처리 순서가 굉장히 중요하다고 할 수 있다.
그렇다면 만약에 CPU bound 프로세스보다 I/O bound 프로세스가 많다면 이 알고리즘의 효율은 어떨까? 당연히 대기 시간이 늘어나고 효율은 떨어지게 되는데 이러한 효과를 Convoy Effect, 호송 효과라고 한다. 호송하는 차량때문에 호송당하는 차가 늦게 갈 수 밖에 없는 것처럼 처리시간이 긴 프로세스가 앞에 오게 된다면 뒤의 프로세스들의 대기시간은 길어지게 된다.
SJF
이러한 FCFS의 호송 효과를 줄이기 위해 등장한 알고리즘이 바로 SJF이다. Shortest-Job-First라는 이름처럼 가장 짧은 CPU burst 시간을 가진 프로세스를 가장 먼저 처리하는 알고리즘이다. 만약 처리 시간이 같다면 FCFS로 처리해주면 된다.

이 또한 간트 차트를 통해 살펴보면 가장 짧은 순서대로 처리되는 것을 볼 수 있다. 평균 대기 시간을 살펴보면 (3+16+9+0)/4=7로 FCFS보다 효율이 좋다. 대기 시간 측면에서는 최고의 효율을 가지는 알고리즘이라고 할 수 있다.
하지만 문제가 있는데 우리는 CPU burst 시간을 정확하게 알 수 없다는 것이다. 이를 보완하기 위해 과거를 통해 근사치를 예측하는 방법을 사용할 수 있다. 여기에는 지수평균이 쓰이는데 이는 최근 데이터에 더 가중치를 주어 최근 경향이 더 많이 반영되도록 하기 위함이다.
$\tau_{n+1}=\alpha \tau_{n}+(1-alpha)\tau_{n}$
하지만 이렇게 동작하는 방식은 엄청나게 큰 예측치를 메모리에 저장하고 있어야 하고 또 다른 리소스를 사용하게 되기 때문에 너무 현실적이지 못한 이상적인 방법이라고 할 수 있다. 또한 선점, 비선점 둘 다 사용할 수 있지만 아무래도 짧은 프로세스를 먼저 실행시킬 수 있도록 선점형으로 하는 것이 유리하긴 하다. 하지만 남은 시간을 알기가 쉽지 않기 때문에 마찬가지로 구현하기가 어렵다.
SRTF
SRTF는 앞서 살펴본 선점형 SJF라고 할 수 있다. 원래 돌아가고 있던 프로세서보다 레디 큐에 있는 프로세서의 CPU burst가 더 짧다면 해당 프로세스를 선점시키는 것이다. 이번엔 조금 다른 방식으로 간트차트를 살펴보자. 각각의 프로세서의 도착시간이 모두 다르다고 가정해보자.


이번에 대기시간을 고려할 때는 프로세스별로 도착시간을 고려해야 한다. 따라서 평균 대기 시간은 ((10-1)+(1-1)+(17-2)+(5-3))/4=6.5이다.
RR
RR 즉, 라운드 로빈 방식은 시분할로 선점적 FCFS를 하는 알고리즘이다. 기본적으로 FCFS 방식을 따라가되 만약 프로세스가 지정한 time quantum안에 작업을 다 마치지 못한다면 자발적으로 프로세스를 릴리즈하는 것이다.

간트 차트에서 볼 수 있듯이 P1은 프로세스가 다 끝나지 않았는데 정해진 time quantum(여기서는 4)가 되자 자동으로 릴리즈되어 다른 프로세스에게 CPU를 양보하였다. 제한시간을 넘어가면 선점되는 것이다. 그렇기 때문에 RR은 time quantum의 영향을 많이 받을 수 밖에 없고, 그것이 따라 성능이 좌지우지 된다.
만약 time quantum이 너무 길어 무한대에 가깝다면 그것은 FCFS처럼 동작할 것이고, 반대로 너무 짧다면 dispatcher latency가 끝나기도 전에 실행이 종료되어 문맥 교환만 계속해서 하게 될 것이다.
Priority-base
priority base는 이름에서 볼 수 있듯이 프로세스의 우선순위에 따라 CPU를 할당해주는 것이다.
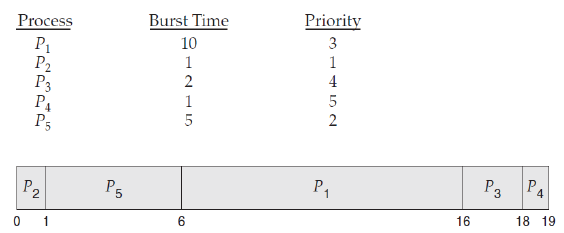
그림에서 볼 수 있다시피 각 프로세스에는 우선순위가 있고 우선순위가 높은 순서대로 프로세스가 실행된다. 하지만 우선순위 스케줄링에서는 큰 문제가 하나 있다. 바로 우선순위가 낮은 프로세스들은 계속해서 CPU를 배정받지 못하는 starvation, 기아 문제가 생길 수 있다. 레디 큐에 있지만 우선순위에 밀려 계속해서 CPU를 배정받지 못하는 것이다. 이 문에를 해결하기 위해 aging 기법을 사용하는데, 시간이 갈수록 프로세스의 우선순위를 높여주는 것이다. 이렇게 되면 낮은 순위를 가진 프로세스도 언젠가는 CPU를 배정받을 수 있게 되고 기아문제가 해결될 수 있다.
대부분의 운영체제는 위에서 살펴본 알고리즘을 하나만 사용하는 것이 아니라 적절히 조합하여 사용한다. 예를 들어 RR과 우선순위 스케줄링을 섞어 시분할을 사용하면서 우선순위가 높은 것을 먼저 실행시키되 만약 우선순위가 같다면 RR 방식을 이용하는 것이다.
Multi-Level Queue(MLQ)
멀티레벨 큐는 레디 큐를 여러 개 두어 각각의 레디 큐에 우선순위를 주는 알고리즘이다. 이렇게 하는 이유는 프로세스도 각각의 특징이 있고 그 특징에 우선순위를 부여하여 효율을 더 높이자는 것이다. 예를 들어 휴대폰은 전화가 가장 우선이어야 하기 때문에 통화 관련 프로세스에 가장 높은 우선 순위를 주는 것이다.
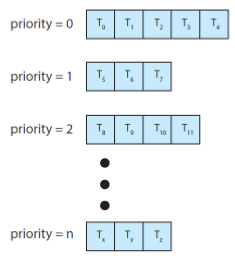
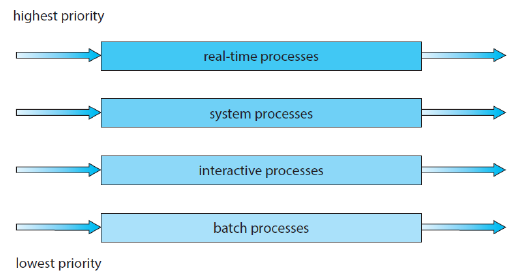
Multi-Level Feedback Queue(MLFQ)
MLQ 또한 우선순위 스케줄링 기법과 마찬가지로 우선순위가 부여되기 때문에 기아 문제가 발생할 수 있다. 따라서 aging과 같은 방법으로 이 문제를 해결한 알고리즘이 Multi-Level Feedback Queue(MLFQ)이다. 우선순위가 낮은 큐일수로 aging을 통해 우선순위를 높여 기아 상태가 발생하지 않도록 보완한 알고리즘이다.
스레드 스케줄링
위에서 살펴본 것들은 프로세스 스케줄링이다. 하지만 현대의 컴퓨터들은 모두 스레드 스케줄링을 사용한다. 그리고 그 중에서도 스레드는 커널 스레드만 스케줄링하면 된다. 유저 스레드는 결국 애플리케이션 단에서 프로그래머가 지정하는 것이고 실제로 동작하는 것은 커널 스레드이기 때문에 유저 스레드는 이러한 커널 스레드에 어떻게 매핑시켜줄 것인지만 고민하는 되는 것이다.
'CS 지식 > 운영체제' 카테고리의 다른 글
| 운영체제 Ch6 - 프로세스 동기화(2) (0) | 2021.12.12 |
|---|---|
| 운영체제 Ch6 - 프로세서 동기화(1) (0) | 2021.12.12 |
| 운영체제 Ch4 - 스레드 (0) | 2021.12.08 |
| 운영체제 Ch3 - 프로세스(2) (0) | 2021.12.08 |
| 운영체제 Ch3 - 프로세스(1) (0) | 2021.12.02 |