지난 포스팅 - 산타 백준 프로젝트 (0) - 프로젝트 개요
📌데이터 정의
본격적으로 크롤링을 하기에 앞서 어떤 데이터가 필요한지를 먼저 정의하는 것이 중요하다. 물론 요새는 데이터 레이크라는 개념이 있어서 우선 모든 데이터를 스토리지에 저장하고 나중에 변환하는 방식을 사용하고는 있다고 한다. 하지만 우리 프로젝트는 데이터 종류가 그렇게 많지도 않고, 사용 데이터가 크게 바뀌지도 않기 때문에 미리 정의하는 것이 좋겠다고 생각했다.
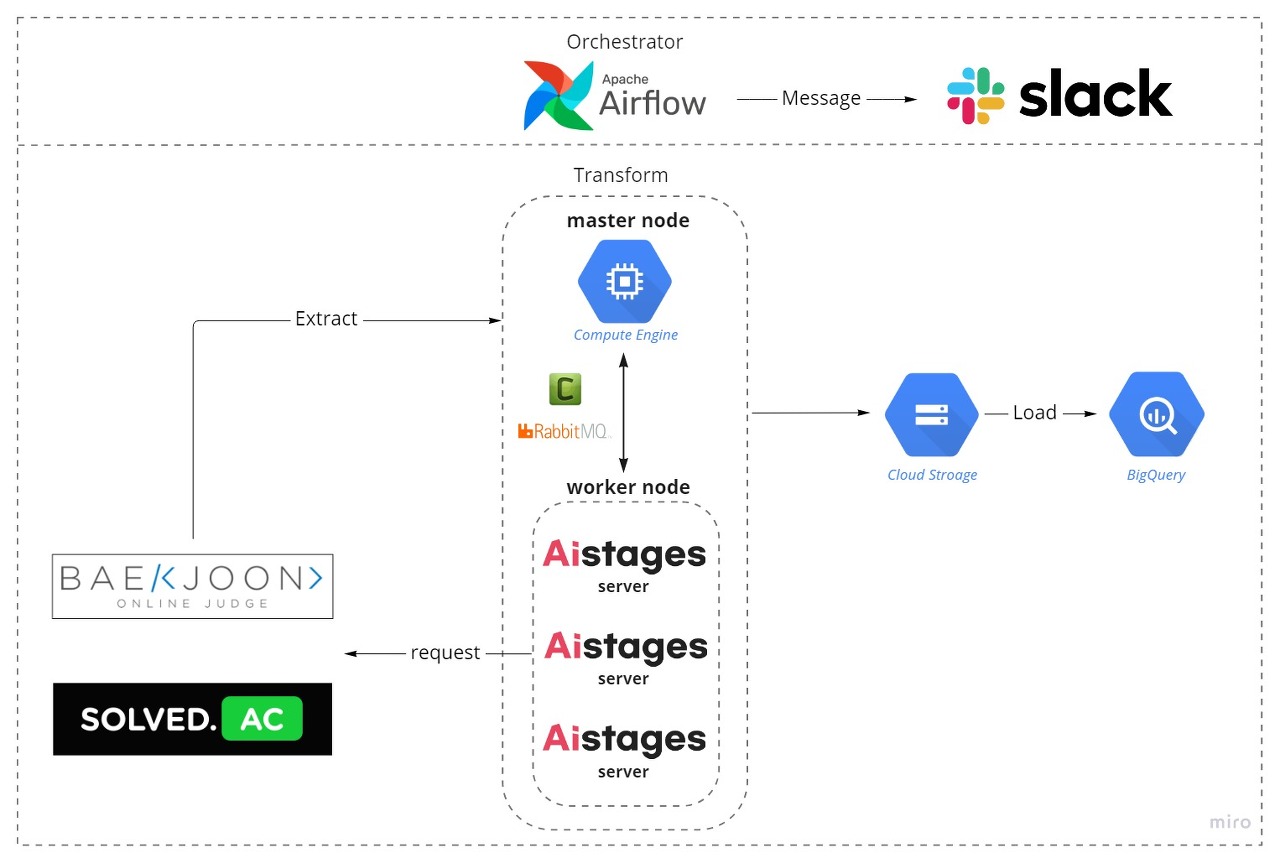
그 전에 프로젝트에서 사용할 데이터 소스에 대해 한 번 설명하고 넘어가는 것이 좋을 거 같다😀 우리는 총 2개의 데이터 소스에서 데이터를 가져오기로 하였다. 백준(BOJ)과 Solved.ac API이다.
백준은 프로그래머라면 모두가 아는 사이트라 설명할 필요가 없을 거 같고, Solved.ac는 백준을 편리하게 이용할 수 있도록 도와주는 서비스이다. 우리는 비공식이지만 Solved.ac에서 제공하는 API와 백준 데이터를 크롤링하여 데이터를 수집하였다.
사용할 데이터를 정의하기 위해 모델링을 하시는 분들과 회의를 하였고, Problem, Score, Course, User 총 4개의 데이터를 수집하는 것으로 결정했다. 그리고 회의 내용을 바탕으로 데이터 정의서를 작성하였다.
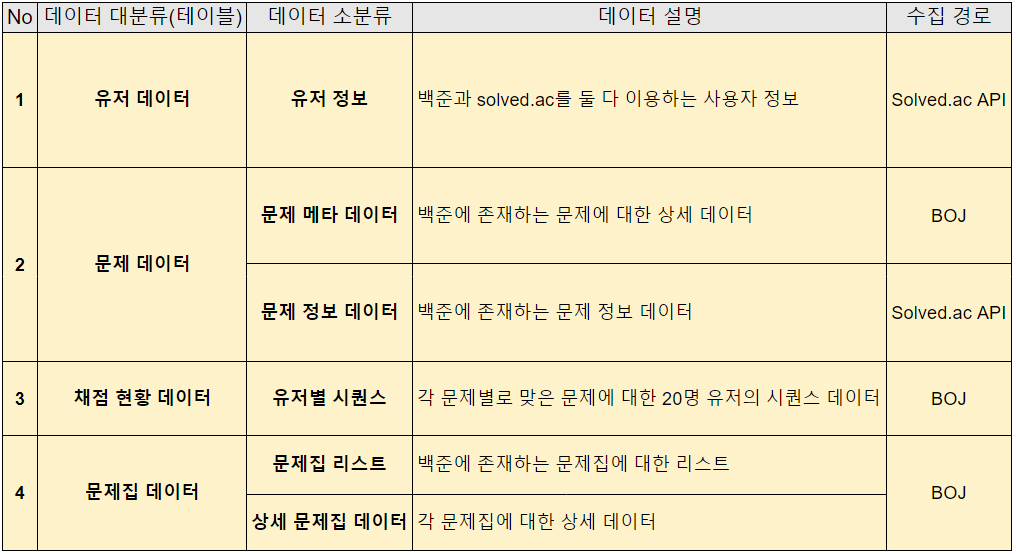
테이블을 이렇게 4개로 분리한 이유는 각 모델마다 사용하는 데이터들이 다르기 때문이다. 우리는 최대한 다양한 추천을 해주는 것을 목표로 하였고, 그렇기 때문에 테이블을 분리하여 관리하기로 하였다. 또한 각 테이블 별로 데이터가 업데이트 되는 주기도 다르기 때문에 이렇게 분리하는 것이 좋겠다고 생각했다. 어쨌든 필요한 데이터를 정의했고, 다음은 이를 수집할 코드를 작성해야했다.
💻스크래핑 코드
이 부분을 자세히 작성할 것인지 정말 많이 고민했다. 결론부터 말하면 스크래핑 코드를 어떤 식으로 작성했는지에 대해서는 자세하게 설명하지 않기로 하였다. 사실 구글링을 하면 스크래핑 코드야 너무나 많이 나오다보니 내가 이에 대해 일일이 설명하는 것이 시간낭비라고 생각했다.(나보다 더 잘하신 분들이 많아서...😎)
핵심만 언급하고 넘어가면 여러 서버가 크롤링을 담당하다보니 워커 노드별로 균등하게 데이터 수집을 담당할 수 있도록 코드를 짰다는 점이다. 이 부분은 Airflow의 Variables이라는 개념이 들어가기 때문에 뒤에 Airflow 부분에서 또 설명하도록 하겠다.
⏩다음은?
오늘 포스팅은 굉장히 짧았다. 분량이 없겠다는 생각은 했지만 이렇게까지 짧아질 줄은 몰랐다... 스크래핑 부분에서 많은 설명을 하지 않아서 조금 이해하기 힘들 수 있을 거 같다. 혹시나 스크래핑 코드가 궁금하다거나 해당 코드에 의문점이 생긴다면 댓글로 질문을 하여도 좋을 거 같다!
다음 글부터는 이제 본격적으로 내가 가장 많이 고민하고 애를 먹었던 Airflow에 대해서 작성해볼 거 같다. 정말 무수히 많은 오류를 만났기 때문에 쓸 내용이 많을 거 같다. 그럼 다음 글에서 뵙도록 합시다!!
'프로젝트 > 산타 백준 프로젝트' 카테고리의 다른 글
| 산타 백준 프로젝트 (2) - Airflow를 이용한 분산 웹스크래핑 | 빅쿼리 구축 (0) | 2022.07.01 |
|---|---|
| 산타 백준 프로젝트 (0) - 프로젝트 개요 (0) | 2022.06.09 |
지난 포스팅 - 산타 백준 프로젝트 (0) - 프로젝트 개요
📌데이터 정의
본격적으로 크롤링을 하기에 앞서 어떤 데이터가 필요한지를 먼저 정의하는 것이 중요하다. 물론 요새는 데이터 레이크라는 개념이 있어서 우선 모든 데이터를 스토리지에 저장하고 나중에 변환하는 방식을 사용하고는 있다고 한다. 하지만 우리 프로젝트는 데이터 종류가 그렇게 많지도 않고, 사용 데이터가 크게 바뀌지도 않기 때문에 미리 정의하는 것이 좋겠다고 생각했다.
그 전에 프로젝트에서 사용할 데이터 소스에 대해 한 번 설명하고 넘어가는 것이 좋을 거 같다😀 우리는 총 2개의 데이터 소스에서 데이터를 가져오기로 하였다. 백준(BOJ)과 Solved.ac API이다.
백준은 프로그래머라면 모두가 아는 사이트라 설명할 필요가 없을 거 같고, Solved.ac는 백준을 편리하게 이용할 수 있도록 도와주는 서비스이다. 우리는 비공식이지만 Solved.ac에서 제공하는 API와 백준 데이터를 크롤링하여 데이터를 수집하였다.
사용할 데이터를 정의하기 위해 모델링을 하시는 분들과 회의를 하였고, Problem, Score, Course, User 총 4개의 데이터를 수집하는 것으로 결정했다. 그리고 회의 내용을 바탕으로 데이터 정의서를 작성하였다.
테이블을 이렇게 4개로 분리한 이유는 각 모델마다 사용하는 데이터들이 다르기 때문이다. 우리는 최대한 다양한 추천을 해주는 것을 목표로 하였고, 그렇기 때문에 테이블을 분리하여 관리하기로 하였다. 또한 각 테이블 별로 데이터가 업데이트 되는 주기도 다르기 때문에 이렇게 분리하는 것이 좋겠다고 생각했다. 어쨌든 필요한 데이터를 정의했고, 다음은 이를 수집할 코드를 작성해야했다.
💻스크래핑 코드
이 부분을 자세히 작성할 것인지 정말 많이 고민했다. 결론부터 말하면 스크래핑 코드를 어떤 식으로 작성했는지에 대해서는 자세하게 설명하지 않기로 하였다. 사실 구글링을 하면 스크래핑 코드야 너무나 많이 나오다보니 내가 이에 대해 일일이 설명하는 것이 시간낭비라고 생각했다.(나보다 더 잘하신 분들이 많아서...😎)
핵심만 언급하고 넘어가면 여러 서버가 크롤링을 담당하다보니 워커 노드별로 균등하게 데이터 수집을 담당할 수 있도록 코드를 짰다는 점이다. 이 부분은 Airflow의 Variables이라는 개념이 들어가기 때문에 뒤에 Airflow 부분에서 또 설명하도록 하겠다.
⏩다음은?
오늘 포스팅은 굉장히 짧았다. 분량이 없겠다는 생각은 했지만 이렇게까지 짧아질 줄은 몰랐다... 스크래핑 부분에서 많은 설명을 하지 않아서 조금 이해하기 힘들 수 있을 거 같다. 혹시나 스크래핑 코드가 궁금하다거나 해당 코드에 의문점이 생긴다면 댓글로 질문을 하여도 좋을 거 같다!
다음 글부터는 이제 본격적으로 내가 가장 많이 고민하고 애를 먹었던 Airflow에 대해서 작성해볼 거 같다. 정말 무수히 많은 오류를 만났기 때문에 쓸 내용이 많을 거 같다. 그럼 다음 글에서 뵙도록 합시다!!
'프로젝트 > 산타 백준 프로젝트' 카테고리의 다른 글
| 산타 백준 프로젝트 (2) - Airflow를 이용한 분산 웹스크래핑 | 빅쿼리 구축 (0) | 2022.07.01 |
|---|---|
| 산타 백준 프로젝트 (0) - 프로젝트 개요 (0) | 2022.06.09 |