개념
가상 메모리란
프로세스를 메모리에 완전히 다 올리지 않아도, 즉 프로그램이 실제 메모리 용량보다 더 커도 실행될 수 있게 하는 기술으로 필요할 때마다 물리 메모리에 매핑시켜 사용한다.
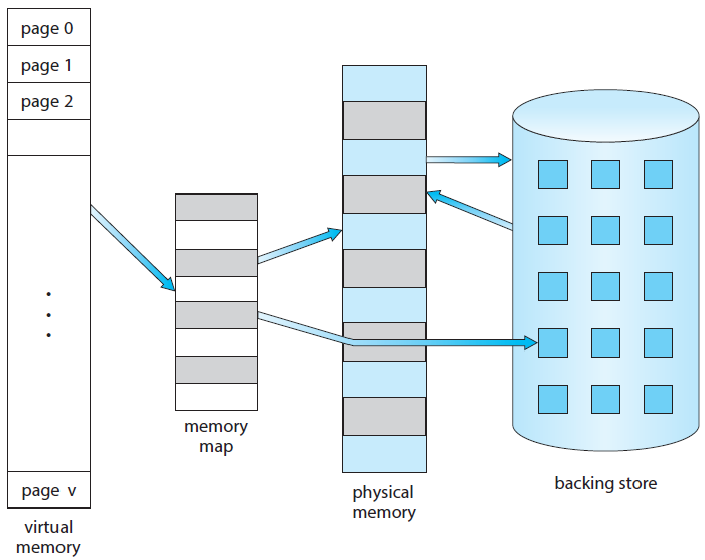
가상 메모리 공간
논리적인 관점으로 프로세스가 메모리에 저장되는 공간. 실제로는 아니지만 연속적인 메모리로써 표현하게끔 하여 프로그램 실행이 굉장히 간편해진다.
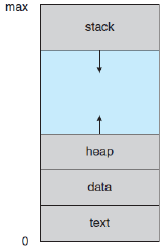
page sharing
가상 메모리는 여러 개의 프로세스가 파일이나 메모리를 공유할 수 있게끔 한다. 이를 page sharing이라 한다.
Demand Paging
Demand Paging 기본 개념
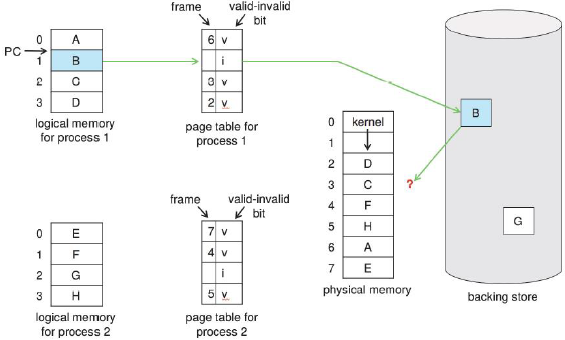
1. 하드 디스크에서 메모리에 프로세스를 로드한다.
2. 한 번에 프로세스를 로드하는 것은 비효율적이므로 요청할 때마다 페이지 단위로 로드한다.
- valid: 페이지가 메모리에 있을 때.
- invalid: 페이지가 메모리에 없고 하드 디스크에 있을 때.
Page fault
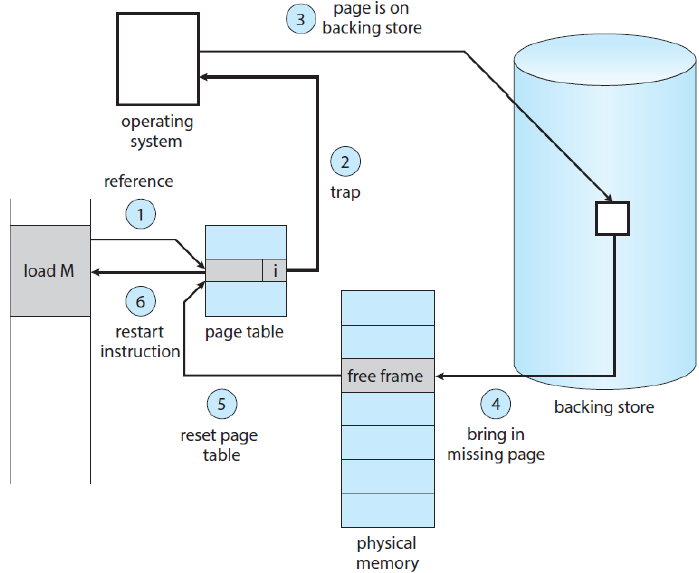
Pure Demand Paging
- 순수하게 정말 요청할 때만 페이지를 가져오는 방법.
- 메모리에는 페이지가 없는 채로 시작하고 정말 페이지가 필요할 때만 OS가 로드해준다.
- 하지만 매번 페이지가 필요할 때마다 로드해야 하기 때문에 효율이 떨어진다. 따라서 페이지를 적당히 많은 수를 한꺼번에 로드해주면 훨씬 효율적일 수 있다.
참조 지역성
- 프로그램을 실행해보면 특정 영역이 계속 반복해서 참조되는 경향이 발견된다. 따라서 Demand Paging을 이용하면 이러한 참조 지역성 덕분에 훨씬 효율적인 성능을 낼 수 있다.
Instruction Restart
- 페이징 아웃되었다가 다시 페이징 인을 하였을 때 동일한 공간, 동일한 상태에서부터 다시 시작할 수 있어야 한다.
- 따라서 명령어를 실행하는 중간에 페이징 아웃이 된다면 명령을 처음부터 다시 시작하여 같은 상태에서 시작할 수 있게끔 한다. (데이터베이스의 원자성과 비슷한 개념으로 이해)
- 예시
1. Fetch and decode the instruction (ADD)
2. Fetch A
3. Fetch B
4. ADD A and B
5. Store the sum in C
만약 B가 페이지 테이블에 없어 페이징 아웃이 되었다면 B를 페이징 인 시킨 후에 다시 1번부터 시작한다.
Free Frame List
- 페이징 아웃으로 인해 메모리 공간이 빈 프리 프레임을 관리하는 리스트.
- stack이나 heap 자료구조로 관리.
Demand Paging의 성능
- EAT = (1-p)*ma + p*(page fault time)
EAT: effective access time
ma: memory access time
p: page fault
=> page fault가 많이 일어날 수록 성능이 저하된다.
- page fault를 처리하는데 가장 지대한 영향을 주는 요소는 페이지를 읽는 시간이다.
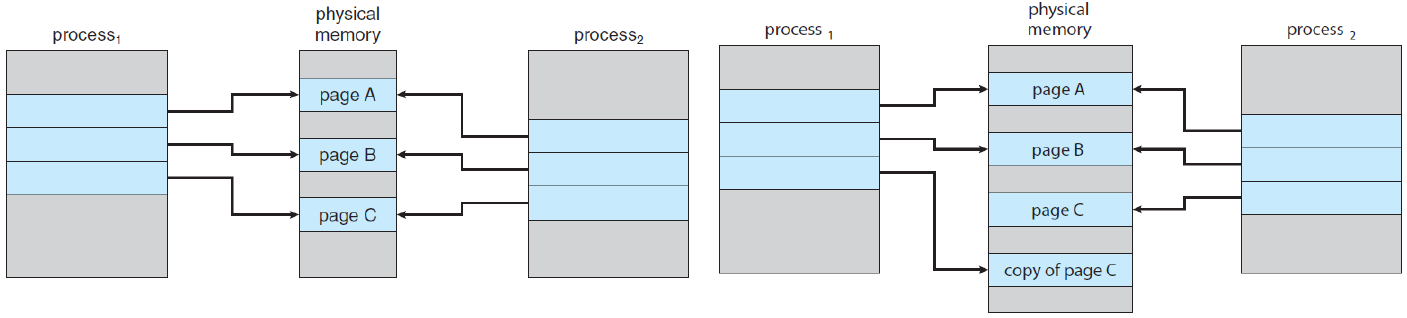
Copy-on-Write
- 만약 여러 프로세스가 공유 페이지를 가지고 있다면, 데이터를 쓸 때만 즉, 데이터에 변화가 있을 때만 페이지를 복사하여 프로세스별로 페이지를 분리해주면 된다.
- 데이터를 읽을 때는 데이터에 어떠한 영향도 없기 때문에 복사하지 않고 사용하면 된다.
Page Replacement
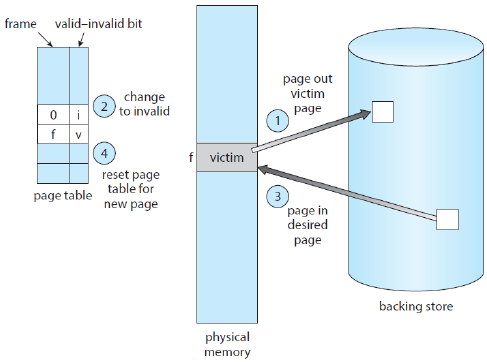
개념
- 만약 갑자기 필요한 페이지 개수가 많아져서 프리 프레임이 부족하다면?
- 페이지 인을 시키려고 보니 자리가 없다 -> 어떤 메모리를 없애고 그 자리에 들어가는 것이 가장 효율적일까 => Page Replacement
- 하드 디스크의 IO 비용이 굉장히 크기 때문에 최대한 page falut를 줄일 수 있는 알고리즘을 선택하는 것이 중요하다.
FIFO Page Replacement
- 선입선출을 따르는 가장 간단한 알고리즘.
- 가장 오래된 페이지를 교체.
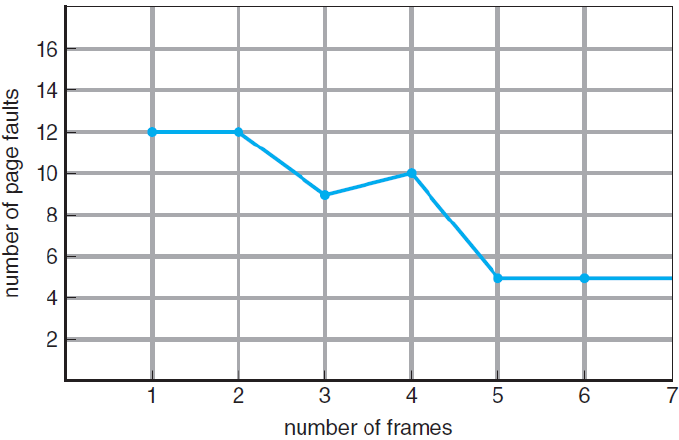
- Belady's Anomaly
FIFO 알고리즘의 가장 큰 문제로써 페이지 프레임을 늘려도 페이지 폴트가 줄지 않는 현상.
Optimal Page Replacement
- 앞으로 가장 사용안 할 것 같은 페이지를 교체.
- 가장 효율적인 알고리즘.
- 하지만 미래 결과가 필요하기 때문에 현실적으로 불가능한 알고리즘.
- 따라서 다른 알고리즘의 평가 기준으로 많이 사용.
LRU Page Replacement
- 미래 결과를 아는 것은 불가능하다 -> 과거를 보면 미래를 알 수 있다!
- 최근 기록을 보고 가까운 미래의 근사치를 예측한다.
- 오랜 기간동안 사용하지 않은 페이지는 앞으로도 사용할 일이 없을 것이다.
- 각 페이지가 마지막으로 사용된 시간을 기록하고 가장 오래된 페이지부터 교체한다.
LRU의 하드웨어 지원
- Counter Implement
페이지 별로 횟수를 기록하여 가장 적은 값을 교체한다. => 횟수가 적다는 것은 많이 쓰이지 않았다는 이야기이고, 이는 가장 오래되었다는 말과 같기 때문이다.
- Stack Implement
스택을 이용한 방법.
Double Linked List를 이용.
접근된 페이지 번호를 top으로 이동.
bottom에 위치한 페이지가 항상 victim이 된다.
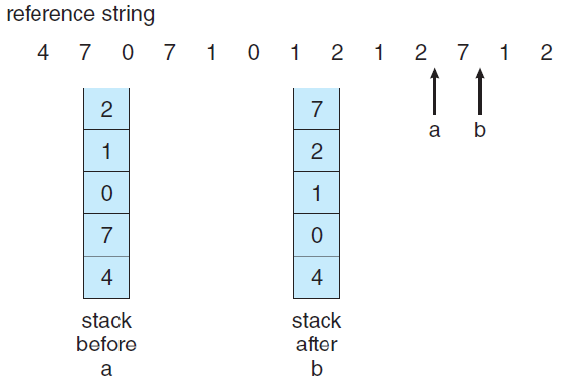
LRU Approximation
- LRU 또한 소프트웨어적으로 구현하기에는 오버헤드도 많이 들고 복잡하기 때문에 하드웨어의 도움을 받아 LRU와 유사한 형태의 교체 알고리즘을 사용한다.
Reference bit
- 초기 모든 페이지는 = 00000000 (8 bit 인 경우)
- 참조가 발생하면 해당 페이지의 reference bits = 10000000
- 가장 작은 reference bits를 갖는 페이지가 victim
Second-Chance Algorithm
- 기본적으로 FIFO
- 도착시간이 가장 오래된 reference bit가 0이면 교체, 1이면 0으로 바꾸고 (도착시간이 현재로 재설정) 메모리에 유지
- 원형 큐를 이용.
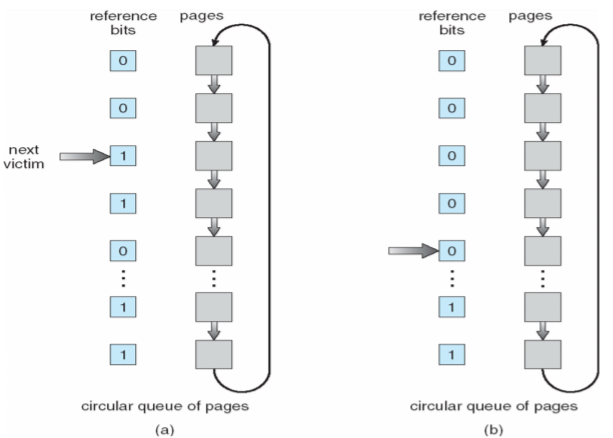
프레임 할당
- n개의 프로세스가 존재할 때 m개의 프레임이 있다면 프로세스별로 몇 개의 프레임을 제공해줄것이냐?
- 프레임이 더 많이 필요한 프로세스에 비례하여 더 많이 배정을 해주어야 할까?
Equal vs Proportional
- equal allocation: 동일한 개수의 프레임을 할당.
- proportional allocation: 프로세스의 크기 비율에 따라 프레임을 할당.
Global vs Local
- local replacement: victim을 자신에게 할당된 프레임에서만 탐색.
- global replacement: 페이지가 없다면 모든 프로세스의 프레임을 대상으로 victim을 탐색.
=> 지역교체는 메모리 사용율이 비효율적이기 때문에 전역교체를 더 많이 사용한다.
Thrashing
- 페이지 인과 아웃을 하느라 프로세스 본인이 해야할 일을 못하는 상황.
- 페이지 수가 충분하지 않다면 페이지 폴트가 많아지면서 나타나는 현상.
(페이지 개수와 스레드 개수가 동일하다면 맨날 페이지 폴트가 일어난다는 말이 이해가 되지 않는다)
Working-Set Model
- 메모리 참조에 지역성이 있기 때문에 window를 지정해놓고 해당 영역에 들어오는 working set은 모두 page in을 하여 관리.
- 이것이 가장 최근에 사용된 페이지일 것이기 때문에 페이지가 사용되었다면 워킹셋 안에 있을 것이고 아니라면 바깥에 있는 것이므로 바깥에 있는 것을 victim으로 선정해주면 된다.
- 따라서 워킹셋만 로딩하도록 제한을 해주면 thrashing 문제도 어느정도 해결된다.
'CS 지식 > 운영체제' 카테고리의 다른 글
| 운영체제 Ch11~15 - 스토리지 관리 (0) | 2022.01.07 |
|---|---|
| 운영체제 Ch9 - 메인 메모리 (0) | 2022.01.05 |
| 운영체제 Ch8 - 데드락 (0) | 2022.01.03 |
| 운영체제 Ch7 - 동기화 문제의 예시 (0) | 2021.12.13 |
| 운영체제 Ch6 - 프로세스 동기화(2) (0) | 2021.12.12 |