카프카 스키마 레지스트리의 주요 동작 방식을 알아보자
스키마 레지스트리는 데이터의 스키마를 관리하고 저장하는 관리형 스키마 저장소이다. 이번 포스팅에서는 스키마 레지스트리의 주요 기능과 동작 방식에 대해 알아보고자 한다.
동작 방식
스키마 레지스트리는 Avro, JSON Schema, Protobuf 3가지의 형식을 지원한다(3가지 형식에 대해서는 다른 포스팅으로 다룰 예정이다). 해당 스키마는 subject 아래에 각각 저장되는데 subject의 이름은 subject name strategy에 의해 정해진다. 디폴트로 subject을 토픽이름으로 하는 TopicNameStrategy을 사용한다.
또한 스키마 레지스트리에는 가장 중요한 기능이라고 할 수 있는 compatibility 즉 호환성 규칙이 있다. 이를 통해 스키마 변경 사항을 어떻게 적용할 것인지에 대한 일종의 규칙을 설립할 수 있다. 해당 내용은 다음에 따로 다룰 예정이다.
스키마 레지스트리는 아래의 그림과 같이 동작한다.
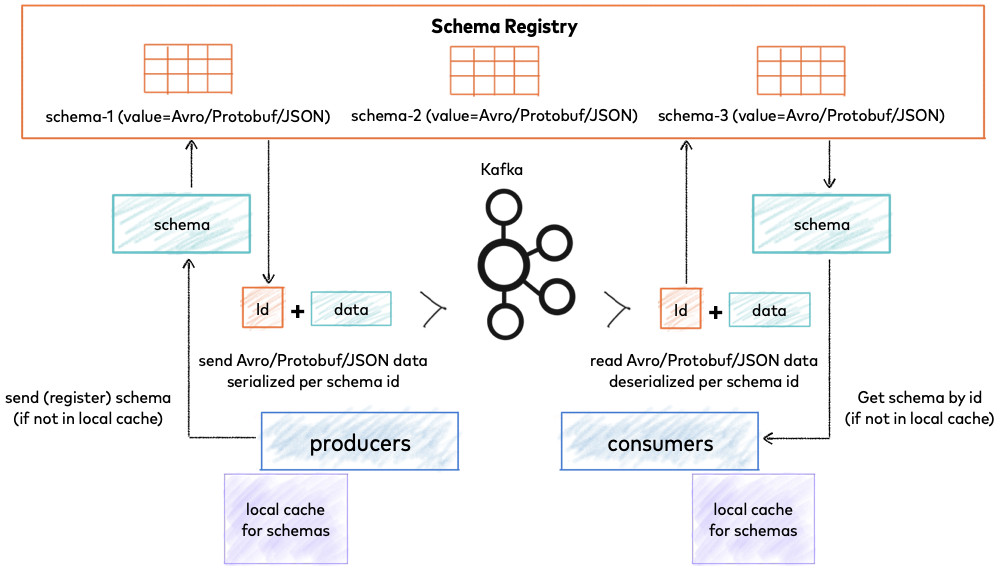
이를 정리하면 다음과 같다.
- 먼저 프로듀서에서 데이터를 전송하면 해당 데이터에 맞게 스키마가 자동으로 등록된다.
- 참고로 스키마를 자동으로 등록하는 기능이 기본으로 켜져있는데 실제 운영 환경에서는 사용하지 않는 것을 권장하고 있다.
- 따라서 프로듀서를 이용해서 자동으로 등록하는 것이 아니라 등록은 따로 관리하는 것이 좋다.
- 데이터를 보낼 때 등록된 스키마의 ID를 가져오고 이를 실제 데이터와 함께 직렬화한다.
- 카프카 스키마 레지스트리에서는 특정한 형태로 데이터를 직렬화하도록 되어 있다.
- 해당 내용은 Wire format 항목을 참고하자.
- 데이터를 직렬화하는 과정에서 스키마를 검증한다.
- 해당 부분은 아직 정확한 이해가 부족한데, 직렬화 과정에서 가져온 스키마를 이용해서 스키마 검증을 한다.
- 직렬화된 데이터를 전송한다.
- 컨슈머에서는 프로듀서에서 한 과정이 역순으로 이루어진다.
- 데이터를 역직렬화를 통해 본래의 상태로 복구한다.
- 스키마 ID로 스키마를 가져오고 이를 통해 스키마 검증을 한다.
참고자료
https://docs.confluent.io/platform/current/schema-registry/fundamentals/index.html
Schema Registry Key Concepts | Confluent Documentation
Schema Registry is a managed schema repository that supports data storage and exchange for both stream processing and data at rest, such as databases, files, and other static data storage. This section explains some fundamental concepts related to schemas,
docs.confluent.io
'데이터 엔지니어링 > Kafka' 카테고리의 다른 글
| 카프카 리밸런싱이란? (0) | 2023.12.16 |
|---|---|
| 쿠버네티스에서 카프카(kafka on k8s) 정말 좋은 선택일까? (0) | 2023.09.11 |