빅데이터를 지탱하는 기술 키워드 정리 - 上
Chapter 1. 빅데이터 기초 지식
Hadoop: 대량의 데이터를 처리하기 위한 시스템
NoSQL: 분산 처리에 뛰어난 데이터베이스
=> 'NoSQL에 저장하고, Hadoop으로 분산 처리'
데이터 파이프라인
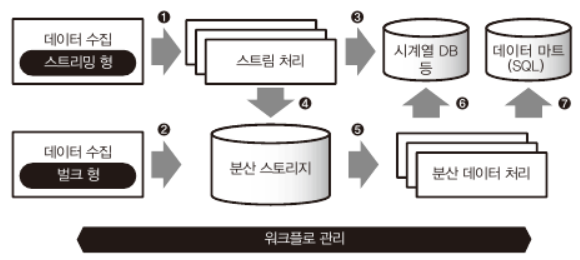
데이터 웨어하우스: 대량의 데이터를 장기 보존하는데 최적화. -> ETL
데이터 마트: DW에서 필요한 데이터만 추출하여 시각화 도구와 조합.
데이터 레이크: DW처럼 가공하여 데이터를 저장하는 것이 아니라 원 데이터를 그대로 저장.
Chapter2. 빅데이터의 탐색
크로스 테이블: 행 방향과 열 방향의 데이터가 교차.
트랜잭션 테이블: DB 형태의 테이블.
피벗 테이블: 소량의 데이터를 크로스 집계.
MPP 데이터베이스: 빠른 데이터 접근을 위해 병렬 처리하는 데이터베이스. 아마존 Redshift와 구글 BigQuery가 있다.
대시보드 도구: 최신의 집계 결과 확인. ex) Kibana
BI 도구: 대화형 데이터 탐색과 같이 차분히 데이터 확인. ex) Tableau
비정규화 테이블: 데이터 마트를 구성할 때 사용하는 테이블 형태로, 팩트 테이블에 모든 칼럼을 포함해두고 쿼리 실행 시에는 테이블 결합을 하지 않아 빠른 속도를 낼 수 있다.
Chapter3. 빅데이터의 분산 처리
데이터 구조화 파이프라인
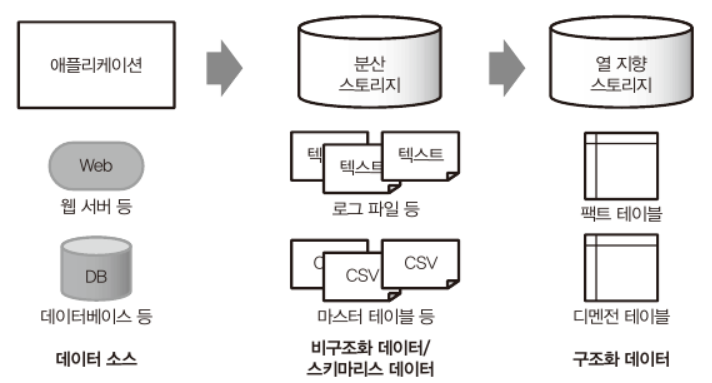
Hadoop
- HDFS: 분산 파일 시스템
- YARN: 리소스 관리자
- MapReduce: 분산 데이터 처리
Hive: MapReduce 기반의 쿼리 언어로 데이터 집계(대용량 배치 처리)
Presto: 대화형 쿼리 실행(Hive로 완성한 구조화 데이터 집계)
Spark: MapReduce를 대체할 고속의 인메모리 분산 데이터 처리
데이터 마트 구축
팩트 테이블에서 필요한 데이터 추출 -> 디멘전 테이블과 결합하여 저장할 컬럼 선택 -> 그룹화하여 측정값 집계 -> 만들어진 비정규화 테이블을 데이터 마트에 축적