스키마리스 데이터의 애드 훅 분석
스키마리스 데이터 수집하기
데이터 소스 -> 트위터 스트리밍 API
분산 스토리지 -> 몽고DB
분산 데이터 처리 -> Spark
데이터 정형 -> pandas
대화식 콘솔 -> 주피터 노트북
트위터 스트리밍 API를 이용하여 몽고DB에 데이터를 적재한다. 수집한 데이터는 주피터 노트북을 통해 대화식으로 볼 수 있는 환경을 마련해준다.
Spark를 이용한 분산 환경
스파크를 이용하여 분산 처리를 할 수 있다. 먼저 몽고DB로부터 데이터를 읽어들이기 위해 데이터프레임을 작성한다.
이 데이터프레임은 Spark SQL을 사용하여 SQL로 집계할 수 있다. 몽고DB는 열 지향 스토리지처럼 읽기에 최적화되어 있지 않아 고속 집계에는 적합하지 않다.
스파크는 데이터 프레임을 토대로 RDD라 불리는 데이터 구조로 되어 있다. 이를 통해 임의의 함수를 Map과 Reduce로 적용할 수 있다.

스파크는 내부적으로 효율적인 데이터 처리를 위해 지연 평가가 있다. 따라서 각 단계별로 코드가 실행되는 것이 아니라 마지막 action을 통해(여기서는 show()) 순차적으로 실행된다. 또한 몇 번이고 똑같은 결과를 반복하는 것은 효과가 나쁘므로, 어느정도 정리한 상태에서 구조화된 데이터를 열 지향 스토리지에 변환하여 물리적인 테이블로 보관한다.
데이터 마트 구축하기
시각화에 적합한 데이터 마트를 만드는 선택지
- Spark에 JDBC로 접속하기
- MPP 데이터베이스에 비정규화 테이블 만들기
- 데이터를 작게 집약하여 CSV 파일에 출력하기
데이터 마트를 구성할 때는 카디널리티를 최대한 줄이는 것이 중요하다. 예를 들어 트위터 단어의 개수가 너무 적다면 그것은 시각화에 큰 메리트가 없으므로 일정 개수 이하의 데이터는 제거한다.
BI 도구로 데이터 시각화하기
BI 도구를 사용하면 조금 더 큰 레코드 수를 가지고 있어도 유연하게 대응할 수 있다. 시각화의 결과를 조금 더 정교하게 하기 위해서 노트북과 BI 도구를 왔다갔다 해가며 처리를 반복한다.
Hadoop에 의한 데이터 파이프라인
데이터 소스 -> 몽고DB
벌크 형 데이터 전송 -> Embulk
분산 시스템 -> Hadoop
데이터 구조화 -> Hive
쿼리 엔진 -> Presto
일일 배치 처리를 태스크화하기
정기적으로 데이터를 전송하고 집계한 후 데이터 마트를 만드는 데이터 파이프라인을 고려해보자.
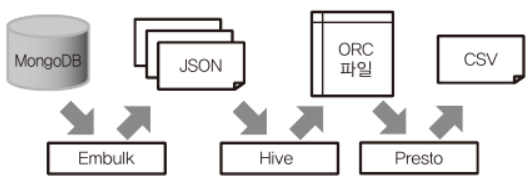
Embulk를 이용한 데이터 추출
Embulk는 데이터를 추출하기 위한 오픈 소스 벌크 전송 도구이다.
지정된 기간의 데이터를 지정된 장소로 써냄으로써 이 태스크의 실행은 멱등하게 된다.
추출한 데이터는 분산 스토리지에 전송하거나 Hive로부터 안정적으로 읽어낸다.
Hive를 이용한 데이터 구조화
앞서 작성한 JSON 파일을 파라미터를 바꿈으로써 시간으로 파티션이 분할된 시계열 테이블로 변환할 수 있다.
자세한 코드는 책의 248~250p를 참고하면 된다.
Presto를 이용한 데이터 집계
Presto는 애드 혹 분석에서 사용되는 대화식 쿼리 엔진이다. 1대의 컴퓨터로도 1000만건이 넘는 테이블을 수초 만에 집계할 수 있다. 열 지향 스토리지를 만드는 것과 비교해 훨씬 고속이므로, 장기간 집계를 다시 실행해도 빠르다. 따라서 매일 데이터 마트를 다시 만드는 편이 간단하다.
이렇게 만든 CSV 파일을 분산 스토리지에 전송하거나 BI 도구에 읽어 들임으로써 최종적인 데이터 파이프라인이 완성된다. 이후에는 파라미터를 교체해서 매일 실행하도록 하면 자동화를 할 수 있다.
워크플로 관리도구를 이용한 자동화
Airflow
Airflow 워크플로는 여러 태스크로 이루어진 DAG로 정의한다. 태스크 간에 의존 관계를 정의해두면, 순서대로 실행되고, 그렇지 않다면 병렬로 실행된다.
태스크를 만들기 위한 클래스를 Operator라고 부른다. 굉장히 다양한 오퍼레이터가 있고 가장 많이 사용하는 것이 BashOperator와 PythonOperator이다.
워크플로를 터미널로 실행하기
airflow test
개별 태스크를 테스트할 수 있다. 결과는 데이터베이스에 저장되지 않으므로 마음껏 테스트할 수 있다.
airflow backfill
DAG에 포함되는 모든 태스크를 실행할 수 있다. 이 경우는 실행 결과가 데이터베이스에 저장된다.
Airflow를 이용한 개발에서는 테스트를 통해 개별 태스크를 확인하고, 제대로 동작한다면 백필로 과거 데이터를 처리한다. 마지막으로 스케줄러에 의한 정기적인 실행을 유효로 하여 계속적인 운용을 한다.
스케줄러를 가동하여 DAG를 정기 실행
이제 실제 운용을 위하여 설정을 변경한다. 예를 들어 병렬 처리를 위해 DB를 MySQL로 전환한다.
스케줄 실행을 시작하려면, airflow scheduler 명령으로 스케줄러를 기동한다. 이는 항시 기동해둔다.
스케줄 설정
모든 DAG는 적어도 schedule_interval과 start_date를 지정해야 한다. cron 형식을 사용할수도 있고 @daily와 같은 생략형을 지정할 수도 있다. 주의사항으로는 DAG의 경우 스케줄 간격 끝날 때 실행된다. 예를 들어 1월 1일의 태스크는 1월 1일이 끝나는 1월 2일 00:00에 실행된다.
태스크 자원 관리하기
원칙적으로 태스크의 실행 시간은 그다지 길어지지 않도록 해서 항상 여유 있는 상태를 유지하도록 한다. 태스크의 동시 실행을 제한하기 위해 자원 풀의 구조를 활용할 수도 있다.
또한 수초 만에 종료하는 작은 태스크나 수천을 넘는 대량의 태스크 실행은 Airflow에 적합하지 않으므로 적절히 모아서 하나의 태스크로 하는 편이 좋다.
태스크 분산 처리
Airflow에서는 분산 처리를 위해 CeleryExcutor나 MesosExecutor를 이용할 수 있다.
클라우드 서비스를 이용한 데이터 파이프라인
AWS
아마존의 AWS는 빅데이터 분야에서 가장 점유율이 높은 클라우드 서비스이고 다양한 서비스를 골라서 이용할 수 있다.

아래는 AWS를 이용한 데이터 파이프라인의 예이다.

GCP
구글의 GCP는 AWS에 이어 대규모 데이터 처리를 실행할 수 있는 클라우드 서비스를 제공하고 있다.

이 또한 마찬가지로 데이터 파이프라인을 구축할 수 있다. 특징적인 것은 데이터 플로우 방식을 서비스화한 Google Cloud Dataflow와 노트북을 서비스화한 Google Cloud Datalab이다.

※ Redshift와 BigQuery의 차이점
둘 모두 데이터 웨어하우스를 위한 클라우드 서비스로 자주 비교된다. 하지만 내부 구조는 완전히 다르다.
가장 큰 차이는 Redshift는 스토리지와 계산 노드가 일체화된 전용 리소스이고, BigQuery는 수천 대의 하드 디스크에 데이터를 분산함으로써 고속화를 실현하는 공유 리소스를 사용한다. 각각의 장점이 있는데, Redshift는 자원이 전용이라 성능이 안정적이고 데이터양에 대해 일정한 성능이 유지된다. BigQuery는 디스크를 공유하여 사용하기 때문에 자신의 노드를 관리할 필요가 없는 풀 매니지드 서비스가 된다.
'데이터 엔지니어링 > 데이터 엔지니어링 기초' 카테고리의 다른 글
| 빅데이터를 지탱하는 기술 키워드 정리 - 上 (0) | 2022.03.18 |
|---|---|
| 데이터 웨어하우스란? (0) | 2022.03.17 |
| 빅데이터를 지탱하는 기술 Ch5 - 빅데이터의 파이프라인 (0) | 2022.01.03 |
| 빅데이터를 지탱하는 기술 Ch4 - 빅데이터의 축적 (0) | 2022.01.03 |
| 빅데이터를 지탱하는 기술 Ch3 - 빅데이터 분산 처리 (0) | 2022.01.03 |